NLP的核心任务:understanding and synthesizing
NLP输入预处理
Tokenization

Case folding
将输入统一大小写,以减少内存,提高效率 ,but可能创造歧义,so具体问题具体分析
For example
"Green"(name) has a different meaning to"green"(colour) but both would get the same token if case folding is applied.
Stop word removal
移除一些含义较少的词,同样提高效率,but可能造成语义不完整,具体问题具体分析
Examples include,
"a","the","of","an","this","that".For some tasks like topic modelling (identifying topics in text), contextual information is not as important compared to a task like sentiment analysis where the stop word"not"can change the sentiment completely.

Stemming
去除单词后缀,可能导致无效词汇,今天很少使用了
Stemming is the act of reducing a word to its stem by removing suffixes .For example, the words
"developed"and"developing"both have the stem"develop".
Lemmatization
将单词化为其词根,可能失去时态信息
For example, the words
"did","done"and"doing"would be converted to the base form"do".
并不是见到一个词就化为其词根,还要考虑词性noun, verb or adjective
For example, it might not modify some adjectives so not to change their meaning. (
"energetic"is different to"energy").
Lemmatization一般被用来代替Stemming

Part-of-speech tagging
决定一个词的词性是noun, verb, adjective,这对于哪些有多个词性的词很有用。
For example, when we say
"Hand me a hammer.", the word"hand"is a verb (doing word) as opposed to"The hammer is in my hand."where it is a noun (thing) and has a different meaning.
Named Entity Recognition
命名实体识别
Common examples include a person, cities, countries and companies.
存在一词多意问题
e.g. Amazon - river or company?
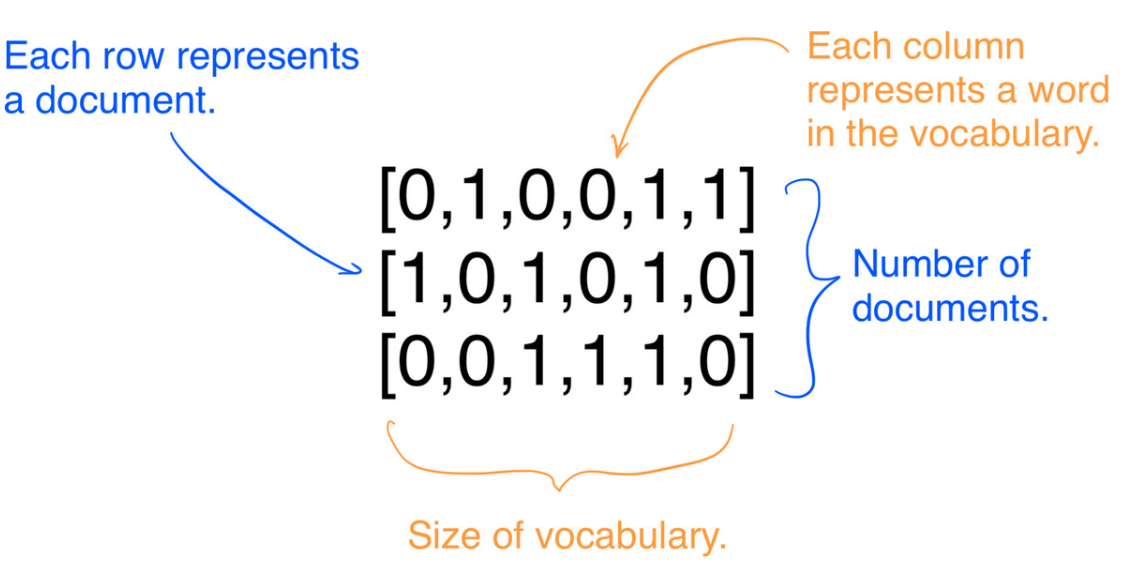
Bag-of-Words
通过统计词频,来计算相似度(这里就可以使用 remove stop words)
下面是Binary Bag-of-Words,仅计入当前词是否存在。
每一行对应一个文档,每一列对应一个词是否存在(在非Binary Bag-of-Words中,将是该词的频率)
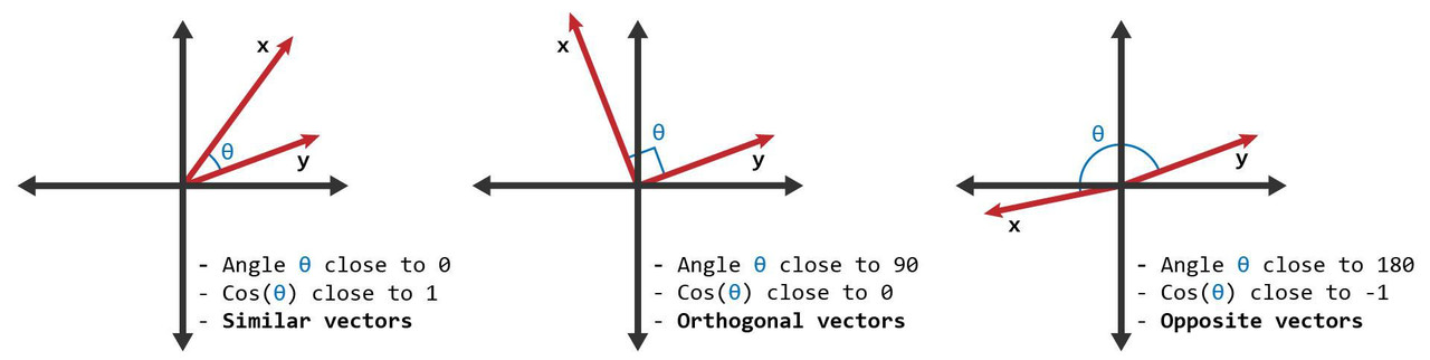
相似度Similarity
将tokens放到空间模型中,距离越近的点,越相似,这里使用余弦相似度Cosine Similarity,值越小越相似
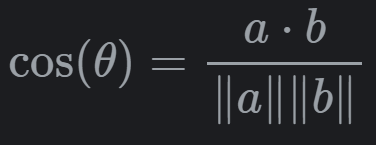
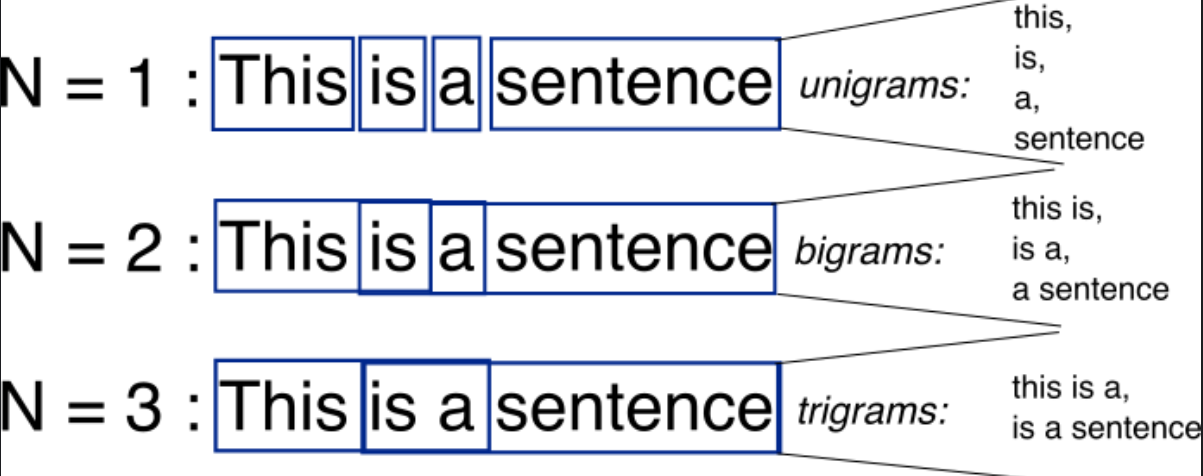
n-grams
将n个词作为一个单位,以此保留一些序列信息