NVIDIA-MambaVision
摘要
主要工作:integrating Vision Transformers (ViT) with Mamba,
目的:improves its capacity to capture long-range spatial dependencies
适用于哪些下游任务:object detection, instance segmentation,and semantic segmentation
引言
transformer训练成本高:the quadratic complexity of the attention mechanism with respect to sequence length makes Transformers computationally expensive to train and deploy
本篇的前置知识:Vit、Mamba、SSM 等
Mamba
通过 new State Space Model (SSM) 关注该关注的,通过ardware-aware considerations并行计算:new State Space Model (SSM) that achieves linear time complexity,enables efficient input-dependent processing of long sequences with ardware-aware considerations.
与NLP问题不同(从左向右推理没什么大问题),CV问题往往需要从全局信息推理局部信息。如将分出的图片patch按行排列,则左上角的图片与其下方的图片距离过远。
the Mamba’s autoregressive formulation,limiting its ability to capture and utilize global context in one forward pass
Vim引入双向SSM来解决这种全局推理局部的问题。
Vision Mamba (Vim) and others have proposed modifications such as bidirectional SSMs to address lack of global context and spatial understanding.
问题:
既然说NLP领域从左到右的因果关系处理问题不大,那么为何会有双向RNN呢?
reply:
双向RNN是为了在NLU - 自然语言理解阶段,消除歧义;而单向的RNN用于NLG - 自然语言生成,如翻译任务。
本文模型的结构:
our proposed formula- tion (i.e. MambaVision Mixer and MLP) as well as Trans- former blocks.
CNN处理高分辨,SSM&self-attention处理低分辨
MambaVision takes the opposite approach with CNNs at higher resolutions and SSM/self-attention at lower ones 相关工作里提到
金字塔结构:不同模块处理不同分辨率,这里用了mamba block、cnn block
MambaVision model which consists of a multi-resolution architecture and leverages CNN-based residual blocks for fast feature extraction of larger resolution features.
self-attention blocks添加在最后一层能够增强global context and long-range spatial dependencies能力:
self-attention blocks at the final stages can significantly enhance the capability to capture global context and long-range spatial dependencies.
评价指标:image throughput、accuracy
image throughput(图像吞吐量):单位时间内处理的图片数量;
公式: $Throughput = \frac{Total\ Images\ Processed}{Total\ Time\ (seconds)}$
知识准备
Stage 1-2
Gaussian Error Linear Unit activation function and batch normalization
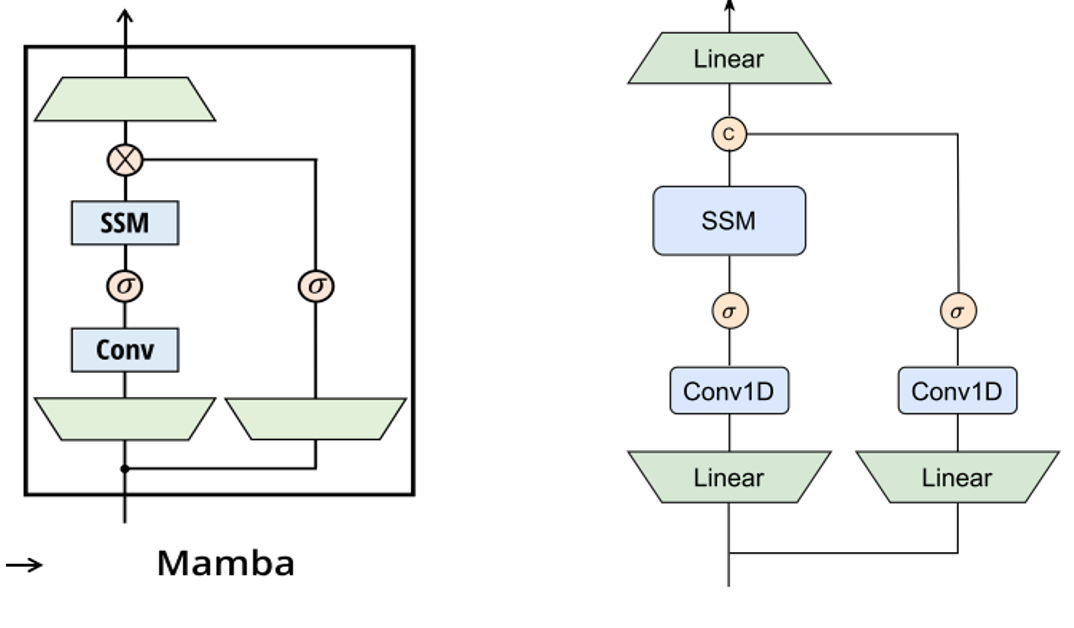
MambaVision mixer
Mamba mixer 与当前的 MambaVision mixer
we redesigned the original Mamba mixer to make it more suitable for vision tasks
Mamba 的selective scan operation, SiLU的sigma激活函数
Scan is the selective scan operation as in [7] and σ is the activation func- tion for which SiLU is used.
SiLU 函数的表达式非常简单:
$f(x) = x \cdot \sigma(x)$
其中 $\sigma(x)$ 是标准的 Sigmoid 函数:
$\sigma(x) = \frac{1}{1 + e^{-x}}$
Transfomer block
注意力的计算方法 windowed manner ,查看两版swin transformer
our framework allows for computing the attention in a windowed manner
结构初步理解
一个stem+4个stage,每个stage间用一个Downsample(下采样)连接。
stem
处理$W*H*3$的输入,其中利用两个$3*3$大小、步长为2的卷积核,投影到embedding space 得到$\frac{W}{4}*\frac{H}{4}*C$。 ⚠️注意:这里的投影并不是用全连接层来实现
stage1-2
分别有两个CNN Block组成。
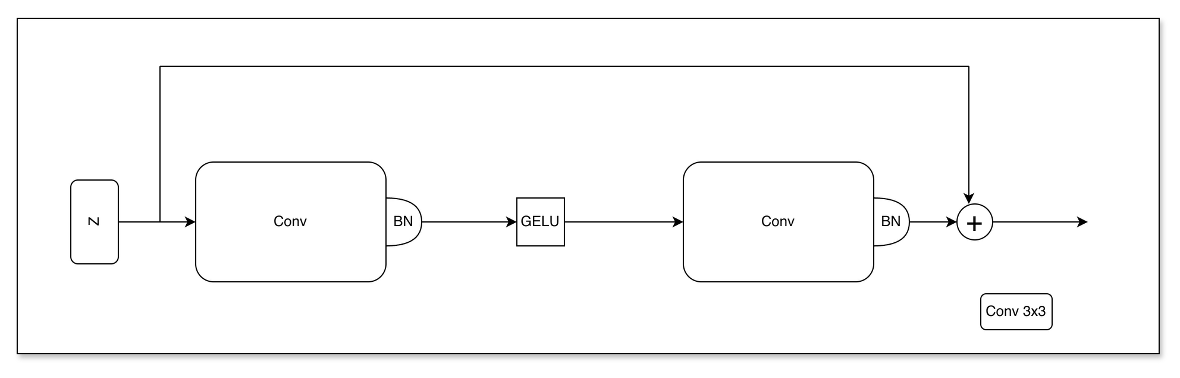
CNN Block的处理过程:
$\hat{z} = GELU(BN(Conv_{3\times3}(z)))$
$z = BN(Conv_{3\times3}(\hat{z})) + z$
具体描述:
第一步 (特征提取与激活):
输入 $z$ 经过一个 $3 \times 3$ 卷积层 提取局部特征 。
接着通过 批量归一化 (BN) 层来稳定训练并加速收敛 。
然后使用 GELU 激活函数 引入非线性,得到中间特征 $\hat{z}$ 。
第二步 (进一步处理):
$\hat{z}$ 再次进入另一个 $3 \times 3$ 卷积层 。
再次进行 BN 化 处理 。
第三步 (残差连接):
- 最后,将处理后的特征与原始输入 $z$ 相加
stem与stage1-2中卷积stride的变化:
| 环节 | 组件 | 步长 (Stride) | 作用 |
|---|---|---|---|
| Stem / Downsampler | 3 \times 3 CNN | 2 | 负责“冲锋陷阵”:缩小尺寸,增加维度 C |
| CNN Block (ResBlock) | 3 \times 3 CNN + BN + GELU | 1 | 负责“精耕细作”:在当前尺寸下深度提取特征 |
Downsample
$H,W$减半,通道翻倍。
前两个stage的输入尺寸变化
| 处理环节 | 分辨率变化 | 通道数 (C) 变化 | 发生位置 |
|---|---|---|---|
| Stem | $H \to H/4$ | $3 \to C$ | 进入 Stage 1 之前 |
| Stage 1 | 保持不变 | 保持不变 | 内部连续执行 $N_1$ 次 |
| Downsample | $H/4 \to H/8$ | $C \to 2C$ | Stage 1 与 Stage 2 之间 |
| Stage 2 | 保持不变 | 保持不变 | 内部连续执行 $N_2$ 次 |
stage3-4
该阶段,每个块中前$\frac{n}{2}$是文章自定义的MambaVision Mixer,后前$\frac{n}{2}$是使用windowed manner进行self-attention计算的Transformer Block
对比mamba block, MambaVision Mixer中增加了对称分支,替换了因果卷积
对称分支:多出旁路的卷积用于增强Mamba模块的局部特征处理能力
常规卷积:用于NLP任务因果卷积,替换为常规的卷积
SSM(S6)模块的流程:从连续到离散
1.输入 x_t会并行通过三个线性投影分支,实时生成该位置特有的参数:
•Delta_t (步长):控制记忆的更新节奏。
•B_t(输入矩阵相关):决定当前像素中有多少信息进入隐藏状态。
•C_t(输出矩阵相关):决定当前状态中哪些信息对输出有用。
2.离散化 (Discretization)
系统利用生成的 Delta_t将连续参数 A和B_t
转化为离散形式:
$\overline{B_t} = \Delta_t B_t$
$\overline{A_t} = \exp(\Delta_t A)$
3.更新状态
$h(t) = \bar{A}h(t-1) + \bar{B}x(t)$
4.输出结果
$y(t) = \bar{C}h(t)$
