VGG16
结构
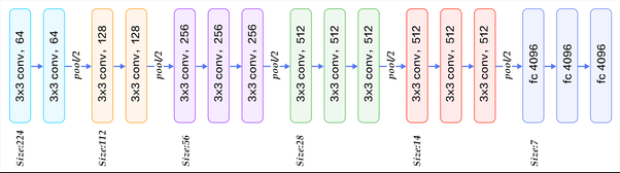
使用TensorFlows实现
def VGG16(input_shape=(224,224,3)):
model = keras.Sequential([
keras.Input(shape=input_shape),
layers.Conv2D(filters=64, kernel_size=(3,3), padding='same', activation='relu'),
layers.Conv2D(filters=64, kernel_size=(3,3), padding='same', activation='relu'),
layers.MaxPool2D(pool_size=(2,2), strides=(2,2), padding='valid'), #这里不same,则尺寸减半
layers.Conv2D(filters=128, kernel_size=(3,3), padding='same', activation='relu'),
layers.Conv2D(filters=128, kernel_size=(3,3), padding='same', activation='relu'),
layers.MaxPool2D(pool_size=(2,2), strides=(2,2), padding='valid'),
layers.Conv2D(filters=256, kernel_size=(3,3),padding='same', activation='relu'),
layers.Conv2D(filters=256, kernel_size=(3,3),padding='same', activation='relu'),
layers.Conv2D(filters=256, kernel_size=(3,3),padding='same', activation='relu'),
layers.MaxPool2D(pool_size=(2,2), strides=(2,2), padding='valid'),
layers.Conv2D(filters=512, kernel_size=(3,3), padding='same', activation='relu'),
layers.Conv2D(filters=512, kernel_size=(3,3), padding='same', activation='relu'),
layers.Conv2D(filters=512, kernel_size=(3,3), padding='same', activation='relu'),
layers.MaxPool2D(pool_size=(2,2), strides=(2,2), padding='valid'),
layers.Conv2D(filters=512, kernel_size=(3,3), padding='same', activation='relu'),
layers.Conv2D(filters=512, kernel_size=(3,3), padding='same', activation='relu'),
layers.Conv2D(filters=512, kernel_size=(3,3), padding='same', activation='relu'),
layers.MaxPool2D(pool_size=(2,2), strides=(2,2), padding='valid'),
layers.Flatten(),#展平
layers.Dense(units=4096, activation='relu'),
layers.Dense(units=4096, activation='relu'),
layers.Dense(units=4096, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['sparse_categorical_accuracy']
)
return model
在猫、狗二分类数据集上进行训练,测试,这里我们使用的是内置的预训练好的VGG16,进行微调即可
我们去掉了预训练的输出层(3个全连接层)
原vgg16
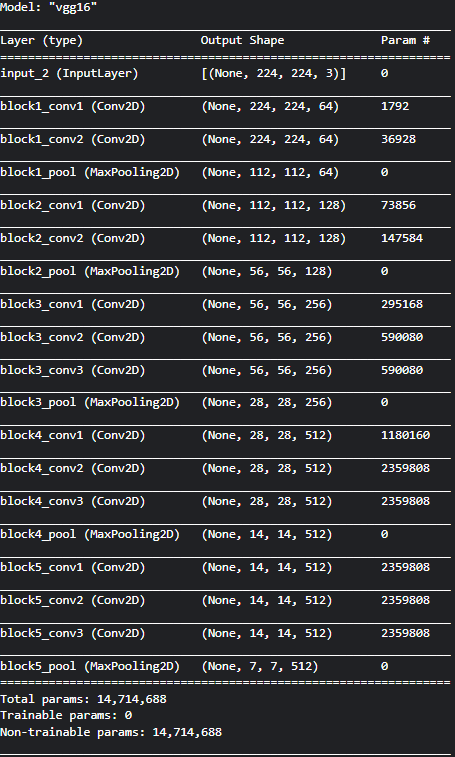
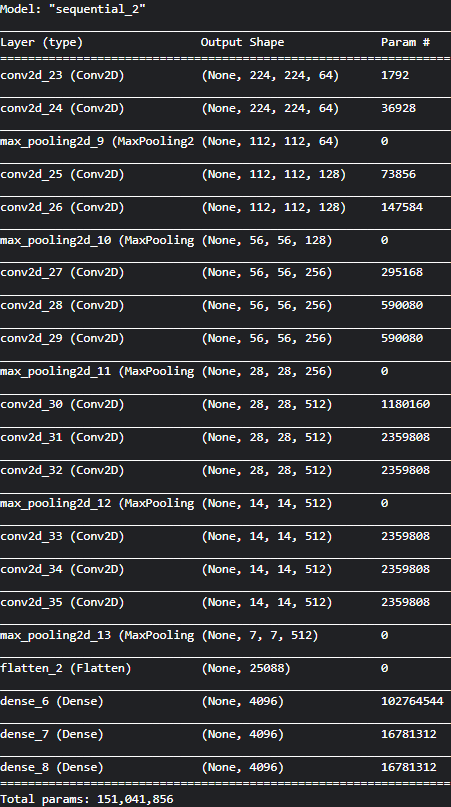 处理后的vgg16
处理后的vgg16
# 设置测试集,训练集目录
test_dir="../input/dogs-cats-images/dog vs cat/dataset/test_set"train_dir="../input/dogs-cats-images/dog vs cat/dataset/training_set" train_dir_cats = train_dir + '/cats'
train_dir_dogs = train_dir + '/dogs'
test_dir_cats = test_dir + '/cats'
test_dir_dogs = test_dir + '/dogs'
# Preview first few images展示前6张图片
preview_cats = ["/cat.1.jpg", "/cat.10.jpg", "/cat.100.jpg", "/cat.1000.jpg", "/cat.1001.jpg", "/cat.1002.jpg"]
preview_dogs = ["/dog.1.jpg", "/dog.10.jpg", "/dog.100.jpg", "/dog.1000.jpg", "/dog.1001.jpg", "/dog.1002.jpg"]
print('Cats')
plt.figure(figsize=(10,8)) #10,8 英寸
for i in range(6):
im_cat = load_img(train_dir_cats + preview_cats[i])
plt.subplot(2, 3, i+1) #展示几行 每行展示几列 i+1 为图所在的子网格位置
plt.imshow(im_cat)
plt.axis('off')
plt.show()
print('Dogs')
plt.figure(figsize=(10,8))
for i in range(6):
im_dog = load_img(train_dir_dogs + preview_dogs[i])
ax = plt.subplot(1, 6, i+1)
plt.imshow(im_dog)
plt.axis('off')#关闭当前子图的坐标轴、刻度和标签
plt.show()
数据加载:
ImageDataGenerator 配合 flow_from_directory 方法,自动完成了将 ‘Cat’ 和 ‘Dog’ 文件夹名称转换为数字标签 0 和 1 的过程。
加载后的数据格式为train_generator[i][j][k],i代表批次,每批64张图片, [j=0]代表该批次的64张图片[j=1]代表该批64张图片的标签,[k]代表该批次某一个图片的标签or图片本身
TARGET_SIZE = (224,224)
BATCH_SIZE = 64
EPOCHS = 50
# Data generator (with data augmentation)
train_generator = ImageDataGenerator(rescale = 1./255, zoom_range = 0.2, rotation_range=10, horizontal_flip=True)#数据增强,随机缩放 旋转 翻转
test_generator = ImageDataGenerator(rescale = 1./255)
# Data flow
training_data = train_generator.flow_from_directory(directory = train_dir,
target_size = TARGET_SIZE,
batch_size = BATCH_SIZE,
class_mode = 'binary')
testing_data = test_generator.flow_from_directory(directory = test_dir,
target_size = TARGET_SIZE,#重新定义图片大小
batch_size = BATCH_SIZE,#分批量加载数据
class_mode = 'binary' #确保了生成的标签 y是一个一维数组,包含整数 0 或 1)
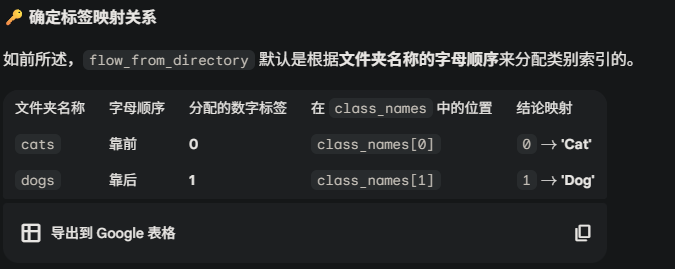
数据集中猫狗文件夹的顺序
构建模型,迁移学习
将 VGG16 应用于不同的任务,比如多标签分类或一个只有 2 个类别的多类别分类任务,只需要**修改最后一层的
units数量和activation函数**
# Add final few dense layers
model = keras.Sequential([
base_model,
layers.Flatten(),#展平
layers.Dense(256, activation='relu'),
layers.Dense(256, activation='relu'),
layers.Dense(2, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['sparse_categorical_accuracy'],
)
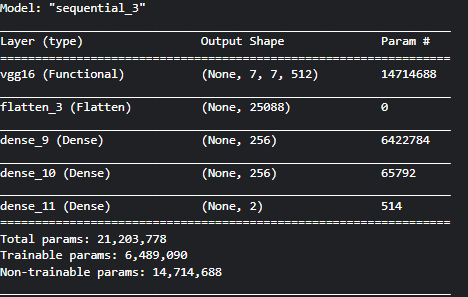
model.summary()
最终的模型
这里最终的2个单元就表示输出2个原始值,经过激活函数softmax 输出概率,模型取概率最大的为其最终类别
开始训练
early_stopping = keras.callbacks.EarlyStopping(
patience = 10,#defines the number of epochs the training will continue after the monitored metric has stopped improving.
min_delta = 0.0001,#the minimum change in the monitored metric that qualifies as an "improvement."
restore_best_weights=True,#停止时权重为迄今为止最好的
)
history = model.fit(
training_data,
validation_data = testing_data,
epochs = EPOCHS,
callbacks=[early_stopping],
verbose=True
)
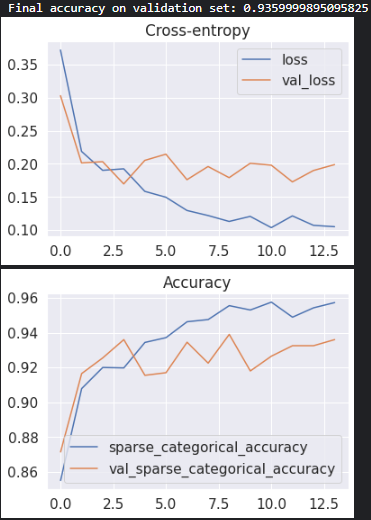
损失和准确率
history_df = pd.DataFrame(history.history)
print(history_df)
history_df.loc[:, ['loss', 'val_loss']].plot(title="Cross-entropy")#提取 DataFrame 中的 训练损失 (loss) 和 验证损失 (val_loss) 数据,并绘制成图。
#.loc: 基于标签选择数据。: (行选择器): 选择 DataFrame 中的所有行。['loss', 'val_loss'] (列选择器): 选择 DataFrame 中名为 'loss' 和 'val_loss' 的这两列。
history_df.loc[:, ['sparse_categorical_accuracy', 'val_sparse_categorical_accuracy']].plot(title="Accuracy")#提取 训练精度 和 验证精度 数据,并绘制成图。
print('Final accuracy on validation set:', history_df.loc[len(history_df)-1,'val_sparse_categorical_accuracy'])#选择最后一行对的稀疏分类准确率
进行预测
preds = model.predict(testing_data)
pred_classes = np.argmax(preds, axis=1) #axis=0 沿着垂直方向(行)操作,找出列中的最大值。 axis=1 沿着水平方向(列)操作,找出行中的最大值。
print(pred_classes)
class_names=['Cat', 'Dog']#猫0 狗1
#testing_data[0]为第一批数据 我们这里数据集是批量处理的 每一批64个图像
#testing_data[0][0]为第一批数据的所有图片
#testing_data[0][1]为第一批数据的所有图片的标签(由加载数据时生成的)
plt.figure(figsize = (20,15))
for i in range(25):
plt.subplot(5,5,i+1)
plt.imshow(testing_data[0][0][i])
if(pred_classes[i] == int(testing_data[0][1][i])):
plt.title(class_names[pred_classes[i]], color='g')
else:
plt.title(class_names[pred_classes[i]], color='r')
plt.axis('off')
plt.show()


Unet
经典的的V结构
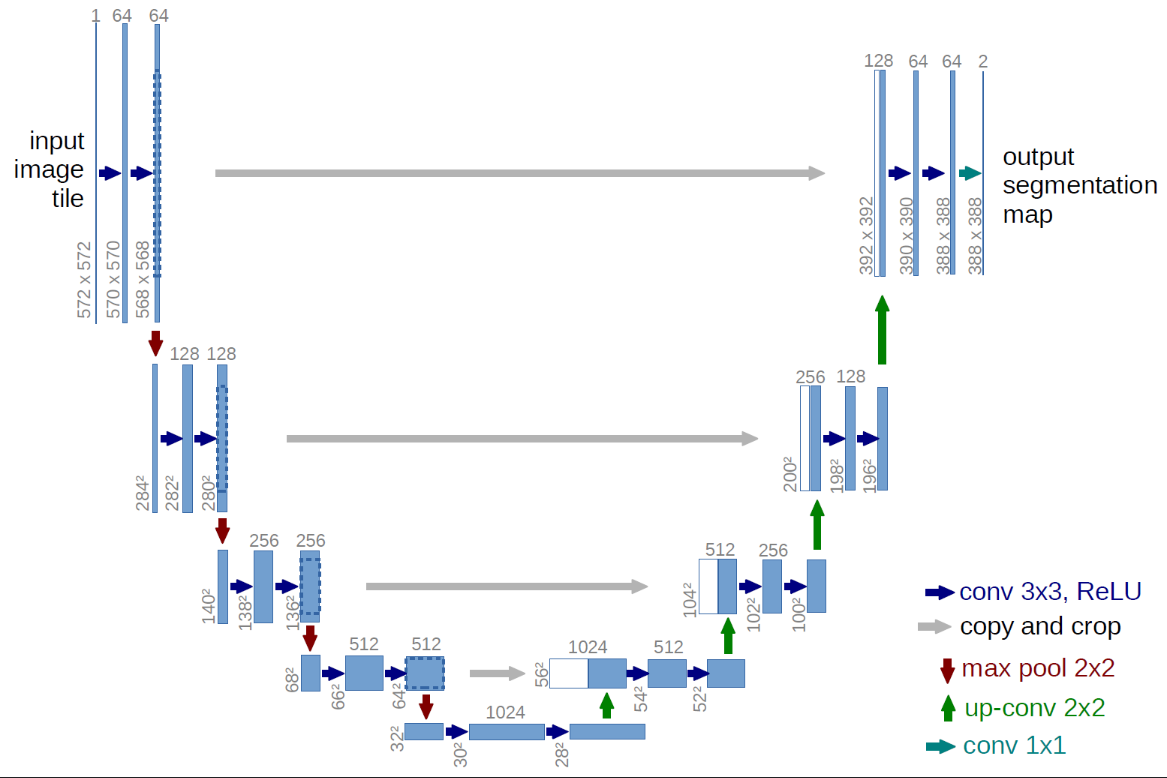
模型
def build_conv(inputs=None, filters=64, max_pooling=True):
conv = layers.Conv2D(filters=filters, kernel_size=(3,3), activation='relu', padding='same', kernel_initializer = 'he_normal')(inputs)
conv = layers.Conv2D(filters=filters, kernel_size=(3,3), activation=None, padding='same',kernel_initializer = 'he_normal')(conv)
#kernel_initializer = 'he_normal'默认带一个权重
# 跳跃连接
skip_connection = conv
conv = layers.BatchNormalization(axis=3)(conv)
conv = layers.Activation('relu')(conv)#写在这是为了上面的跳跃连接
if max_pooling:
next_layer = layers.MaxPool2D(pool_size=(2,2), strides=(2,2))(conv)
else:
next_layer = conv
return next_layer, skip_connection
def build_upsampling(expansive_input, contractive_input, filters=64):#contractive_input来自跳跃连接
#这里默认为何也是64
#反卷积
up = layers.Conv2DTranspose(filters=filters, kernel_size=(2,2), strides=(2,2), padding='same')(expansive_input)#up的特征图尺寸恢复到与 contractive_input 相同的分辨率。它的通道数由 n_filters 决定。
#合并跳跃连接和上采样信息
merge = layers.concatenate([up,contractive_input], axis=3)#axis=3通道维度
#两个卷积
conv = layers.Conv2D(filters=filters,
kernel_size = (3, 3),
activation = 'relu',
padding = 'same',
kernel_initializer = 'he_normal')(merge)
conv = layers.Conv2D(filters=filters,
kernel_size = (3, 3),
activation = None,
padding = 'same',
kernel_initializer = 'he_normal')(conv)
conv = layers.BatchNormalization(axis=3)(conv)
conv = layers.Activation('relu')(conv)
return conv
def build_one_unet(filters=64,input_size=(256,256,3), n_classes=1):
inputs = layers.Input(input_size)
enblock1 = build_conv(inputs, filters)#倒数第二行设置了调用fit时,数据自动传入inputs
enblock2 = build_conv(enblock1[0],filters*2)#每个enblock卷积核数量*2
enblock3 = build_conv(enblock2[0],filters*4)#enblockx[0]为返回的第一个参数,即上一层的特征图
enblock4 = build_conv(enblock3[0],filters*8)
enblock5 = build_conv(enblock4[0],filters*16,max_pooling=False)#第五个不maxpool
deblock1 = build_upsampling(enblock5[0],enblock4[1],filters*8) #不同的是,这里的卷积核逐渐变少
deblock2 = build_upsampling(deblock1,enblock3[1],filters*4)
deblock3 = build_upsampling(deblock2,enblock2[1],filters*2)
deblock4 = build_upsampling(deblock3,enblock1[1],filters)
#最后一个卷积
conv_last = layers.Conv2D(filters = n_classes, kernel_size=(1,1), activation='sigmoid', padding='same')(deblock4)
model = keras.Model(inputs=inputs, outputs=conv_last) #在函数式 API 中,这是模型数据流的起点。在训练模型时,model.fit() 的图像数据会从这个 inputs 张量开始流经整个网络。
return model
语义分割训练,预测待补充…
