Multi-Node
问题
镜像分发:VM2 无法读取 VM1 电脑里的
my-fl-app镜像。 构建镜像,推送到镜像仓库编排不同:K8s YAML是期望,而普通多容器项目定义的是service,每个service对应一个容器;k8s Yaml 的单位是Pod这可能包含多个容器

FL策略
同步(Synchronous
分发:Server 把模型发给选中的 $K$ 个 Client。
训练:所有 Client 开始训练。
等待 (Barrier):Server 必须等待所有(或指定比例)Client 训练完成并回传参数。
聚合:Server 收到最后一份报告后,进行加权平均,更新全局模型。
下一轮:进入下一轮循环。
该策略存储木桶短板问题,即训练耗时取决于性能最低的那一台机器
异步(Asynchronous
独立行动:Client 只要领到任务就去练,练完立刻上传。
即时更新:Server 收到任何一个 Client 的更新,就立刻更新全局模型,不需要等别人。
继续跑:该 Client 拿最新的模型继续下一轮,不管其他 Client 还在干嘛
该策略,存在模型陈旧 (Staleness)问题,假设当前全局模型是 $W_5$(第5版),VM2 跑得慢,它还在用 $W_2$ 训练,当 VM2 终于提交梯度时,Server 已经更新到 $W_{10}$ 了,用基于旧模型 $W_2$ 算出来的梯度,去更新新模型 $W_{10}$,可能会导致模型“指错路”,甚至发散。
Federated Averaging
每轮选取一组设备参与。
公式:
$f(w) \triangleq \sum_{k=1}^{K} \frac{n_k}{n} F_k(w)$
$w$: 全局模型参数
$f(w)$: 全局视角下的损失。假如我们把所有 Client 的数据收集到一个巨大的中心服务器上训练,算出来的 Loss 就是 $f(w)$。
$F_k(w)$: 第 $k$ 个 Client 在自己本地数据上算出来的损失(Local Loss)。
$\frac{n_k}{n}$: 权重系数(数据量越大的客户端,对全局 Loss 的影响越大)。
目标:找到一个 $w^*$,使得 $f(w^*)$ 最小。
FATE
Flow作为大脑,发送指令给container,container加载算法,呼叫Eggroll加载数据计算梯度,返回结果给container,container与对方通过osx交换参数,
拿到对面的聚合好的参数后,container更新本地模型。同时DB记录每一步,Flow把每一轮的损失和精确率写入DB,Board则是面板用于展示每轮结果,如损失,精确率等。
左边的Eggroll有存储数据和计算的功能,而右边HDFS 是存数据的硬盘,Spark 是算数据的内存引擎(将HDFS中的大量数据加载到内存中进行计算)
左边代表定制化架构(Eggroll),追求极致的计算效率;右边代表通用大数据架构(Spark+HDFS),追求对旧资产的兼容。
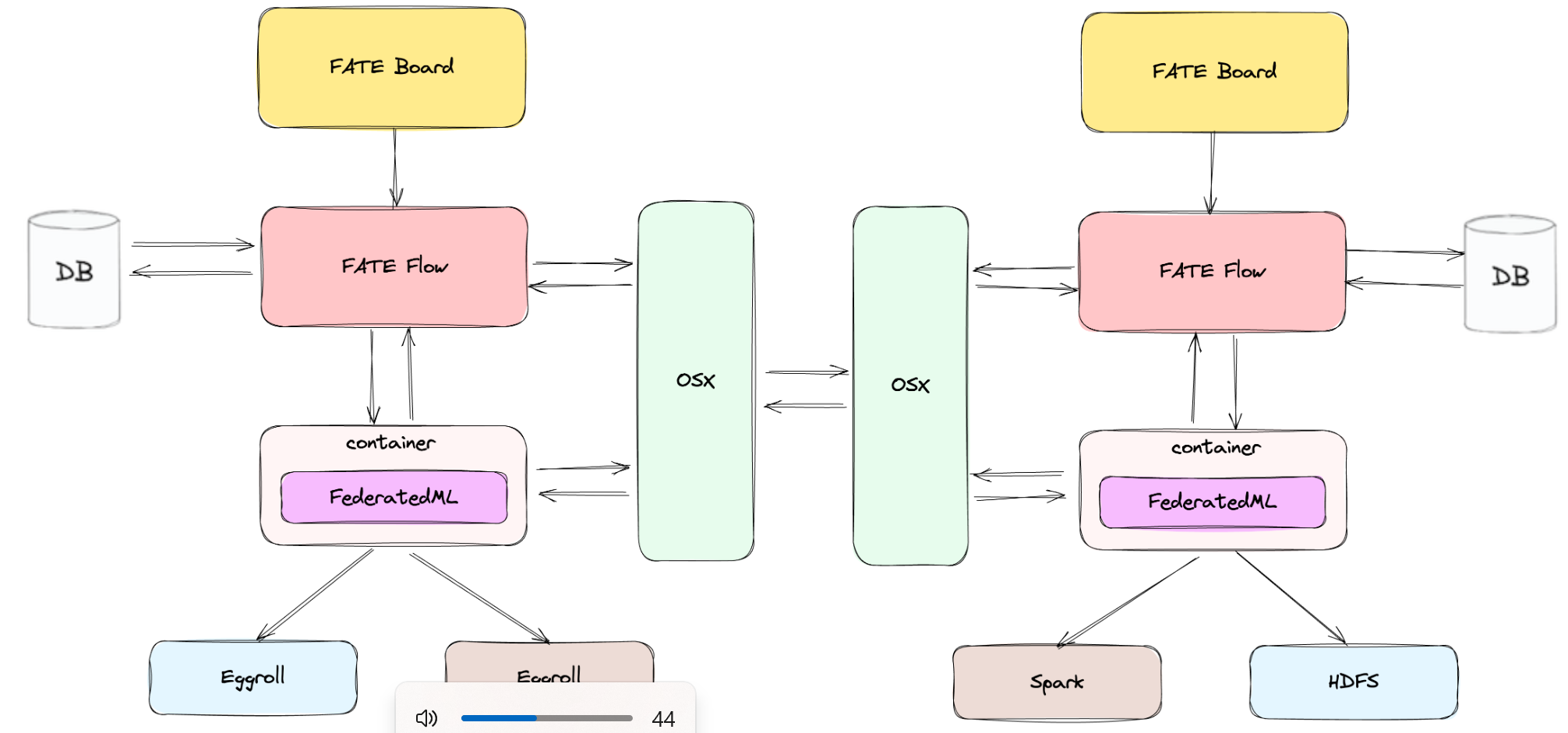
container和Eggroll采用不同语言实现,这带来了跨语言问题,Eggroll加载数据进行序列化,创建python子进程(算法是python代码),用子进程来跑反序列化后的数据,计算的结果经过python子进程序列化后抛给Eggroll,Eggroll返回结果给container,可以看到大量的数据在Egroll和python子进程间反复倒腾。图中这样设计是为了兼顾python的ML生态和Java的大数据生态。idea:Apache Arrow (一种跨语言内存格式)
真正的系统瓶颈:Worker 内部的跨语言调用 (The Real Bottleneck) —— 巨大开销
Eggroll 的 Worker 节点收到了命令和 Python 代码。
Eggroll 的内心独白: “我是 Java/C++ 进程,我内存里有数据,但我跑不了这串 Python 二进制代码啊!”
怎么办? Eggroll 的 Worker 节点会在本地启动一个 Python 子进程 (Python Worker)。
数据流转 (IPC 灾难现场):
Eggroll (Java) 从内存/硬盘读取数据。
序列化: Eggroll 把数据序列化,通过 Socket/Pipe 塞给旁边的 Python 子进程。
反序列化: Python 子进程收到数据,还原成 Python 对象。
计算: Python 子进程调用你写的
encrypt_and_add函数处理数据。再序列化: Python 子进程把结果序列化。
再反序列化: 扔回给 Eggroll (Java) 进程存起来。
原论文中的图
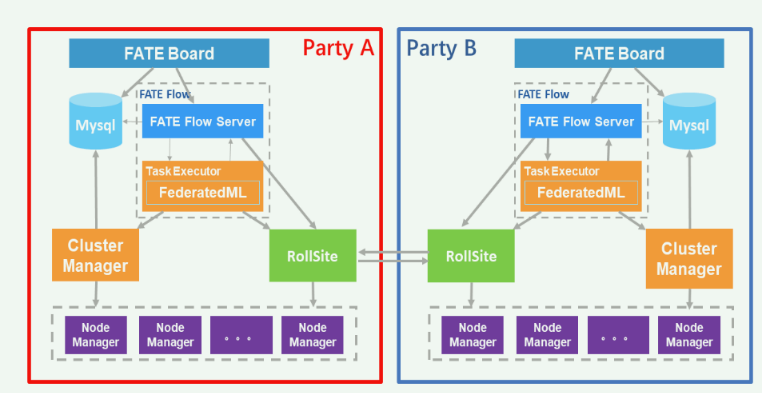
RollSite 的作用:它是跨站点通信的网关(Proxy)。
交换的数据内容:通过 RollSite 交换的不是原始数据。根据 FATE 的安全定义:
对于 HFL (横向联邦):交换的是加密的模型参数或梯度 。
对于 VFL (纵向联邦):交换的是加密的中间计算结果(Intermediate Results),确保各方只获得最终输出而不泄露原始特征 。
Node Manager在容器中就是一个主进程,是负责管理该容器内的子进程的生命周期
具体:
Cluster Manager = 调度器 (Scheduler) / 控制平面
职责:决策(Decision Making)。它决定“谁去做什么”。
状态:持有整个集群的元数据(Metadata)。
Node Manager = 守护进程 (Daemon) / 执行平面
职责:执行(Execution)。它负责“通过系统调用(fork/exec)拉起进程”。
状态:持有单机的实时监控数据(CPU 使用率、内存水位)。
总结:Cluster Manager 是那个看着大屏幕(全局状态)按按钮的人,而 Node Manager 是在机房里根据指令插拔网线(启动进程)的人。
总过程:
用户发起FATE Board 任务,元数据集写入mysql,fateFlow向cluster manager申请计算资源,后者将对各个Node Manager指定资源需求,Node Manager中的子进程负责最终的计算, 计算时是将Task Executor调度到这些容器的子进程上计算? 新启动的子进程会加载 FederatedML 的代码库,它是一个无状态(Stateless)的计算单元,专门负责执行这一轮的数学运算 结果通过Rollsite同外部交换,那么全局模型更新是怎么进行的? 在 FATE(特别是 EggRoll 架构)中,全局更新不是由一个神秘的“中央服务器”完成的,而是通过多方协作的计算流完成的。这与 Google 那种有一个物理上的 Master Aggregator 不同。这里是通过一方的Task Executor 运行聚合代码(例如 FedAvg 算法),算出新的全局模型。 Node Manager子进程计算时所需要的数据又是从哪里来的? 是根据指派任务从分布式存储上加载的。
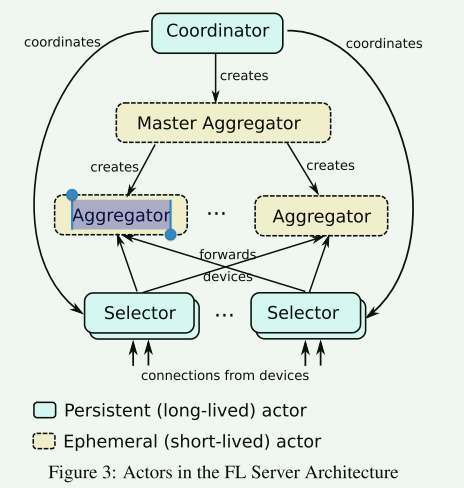
| 功能层级 | Google Cross-Device (图1) | FATE Cross-Silo (图2) | 系统设计差异逻辑 |
|---|---|---|---|
| 总指挥 (Coordination) | Coordinator(全局单点) | FATE Flow(多点协同) | 图1需要一个全局“上帝”来从数亿设备中筛选用户。图2是平等的机构合作,每个机构都有自己的 FATE Flow,双方通过协商(握手)来同步进度。 |
| 连接管理 (Connectivity) | Selector | RollSite | 图1的 Selector 像一个“漏斗”,负责连接数万台手机,剔除掉线的设备,保证每一轮有足够的人参加。图2的 RollSite 像一条“专线隧道”,负责在 Party A 和 Party B 之间建立极其稳定的安全通道。 |
| 计算与聚合 (Aggregation) | Master Aggregator& Aggregators | Task Executor& Cluster Manager | 图1 采用 MapReduce 思想(分层聚合),只是为了把数百万个简单的梯度加起来。图2 采用 EggRoll 分布式计算,是为了运行复杂的加密协议(如同态加密计算),计算密度远高于图1。 |
| 参与者状态 (Actors) | Ephemeral (短生命周期) | Persistent (持久化) | 图1 假设 Aggregator 和设备都是随时可丢弃的(无状态)。图2 假设 Party A/B 是长期在线且可靠的(有状态数据库 MySQL)。功能层级,Google Cross-Device (图1),FATE Cross-Silo (图2),系统设计差异逻辑 总指挥 (Coordination),Coordinator(全局单点),FATE Flow(多点协同),图1需要一个全局“上帝”来从数亿设备中筛选用户。图2是平等的机构合作,每个机构都有自己的 FATE Flow,双方通过协商(握手)来同步进度。 连接管理 (Connectivity),Selector,RollSite,图1的 Selector 像一个“漏斗”,负责连接数万台手机,剔除掉线的设备,保证每一轮有足够的人参加。图2的 RollSite 像一条“专线隧道”,负责在 Party A 和 Party B 之间建立极其稳定的安全通道。 计算与聚合 (Aggregation),Master Aggregator& Aggregators,Task Executor& Cluster Manager,图1 采用 MapReduce 思想(分层聚合),只是为了把数百万个简单的梯度加起来。图2 采用 EggRoll 分布式计算,是为了运行复杂的加密协议(如同态加密计算),计算密度远高于图1。 参与者状态 (Actors),Ephemeral (短生命周期),Persistent (持久化),图1 假设 Aggregator 和设备都是随时可丢弃的(无状态)。图2 假设 Party A/B 是长期在线且可靠的(有状态数据库 MySQL)。 |
问题:
为何不在container中直接算? container无法加载大量数据到内存,会导致container爆炸
这里面container不是容器么?它和计算节点的区别在哪里?计算节点不是容器么? container这里指装着算法的容器用于对装置计算节点的容器发号施令
1. 核心区别:逻辑角色 vs. 物理载体
为了方便理解,我们把 FATE 系统比作一个建筑工地:
A. 图中的 “Container” (FederatedML)
它的真实身份: 任务发起者 / 算法驱动器 (Driver)。
它的工作: 它装着你写的 Python 算法代码(比如逻辑回归的公式)。它负责发号施令。它告诉别人“把这堆数据加起来”、“把那个矩阵乘一下”。
它在哪里: 在 KubeFATE 部署中,它确实被包裹在一个 Docker 容器里运行。
类比:它是包工头。包工头拿着图纸(算法),但他自己不搬砖,他只是指挥工人干活。
B. 图中的 “Eggroll / Spark” (Compute Node)
它的真实身份: 分布式计算引擎 (Distributed Computing Engine)。
它的工作: 它负责真正的苦力。它管理着硬盘上的海量数据,并执行包工头下发的计算指令(加减乘除)。
它在哪里:
逻辑上: 它是被调用的服务。
物理部署上: 重点来了! Eggroll 的每一个节点(Node Manager),本质上通常也是运行在 Docker 容器里的!
类比: 它是工人队伍。他们人多力量大,听包工头指挥。
而在实际的 Kubernetes (K8s) 集群里,情况是这样的:
Pod A (Container): 跑着
FATE Flow(调度)。Pod B (Container): 跑着
FederatedML(刚才图里的那个 Container,负责指挥)。Pod C, D, E… (Compute Nodes): 跑着
Eggroll NodeManager(负责计算)。
所以,大家都是容器。 但在架构图上,为了区分**“谁是指挥(Driver)”和“谁是干活(Executor)”**,特意把指挥官标为了 Container,而把干活的标为了 Eggroll。
图里的 ‘Container’ 实际上是 算法的 Driver(驱动进程),它负责下发指令。
底下的 ‘Eggroll’ 是 分布式 Executor(执行器),负责并行计算。
虽然在 K8s 环境下它们都是以 Docker 容器的形式存在的,但我的研究(跨虚拟机/资源隔离)主要关注的是:如何防止底下的 Executor 容器(Eggroll) 因为计算过载而拖垮物理机,以及如何优化 Driver 容器 和 Executor 容器 之间的通信延迟
论文导读部分
第四部分:去哪里找论文(精准检索)
研一要学会区分“算法顶会”和“系统顶会”。你的方向更偏向后者。
系统领域三大顶会(重点关注):
OSDI (Symposium on Operating Systems Design and Implementation)
SOSP (Symposium on Operating Systems Principles)
NSDI (Symposium on Networked Systems Design and Implementation)
搜索关键词:
Federated Learning+System/Scheduling/Container/Heterogeneity.
机器学习与系统交叉会议:
SysML (Conference on Machine Learning and Systems) —— 这是你的主战场。
EuroSys
具体搜索Query建议(Google Scholar / DBLP):
Federated Learning System Design for HealthcareContainerized Federated LearningFederated Learning over KubernetesCommunication-Efficient Federated Learning in Heterogeneous Systems
我为你精选了 4 篇 最具代表性的论文。这些论文的特点是:系统架构图清晰、工程属性强、与你的“跨孤岛+容器”方向高度重合。
请重点关注它们的 Abstract(摘要)、Introduction(引言) 和 System Design(系统设计) 章节。
其它补充论文:
第一类:工业界架构标杆(必看,用于构建系统观)
这两篇是教你“怎么搭房子”的,里面的架构图可以直接参考来画你自己的系统图。
1. FATE (Webank) —— 跨孤岛的工业事实标准
论文标题: “FATE: An Industrial Grade Platform for Collaborative Learning with Data Protection” (JMLR 2021)
为什么推荐:
它是目前Cross-Silo(跨孤岛) 领域最成熟的开源框架,专门针对金融和医疗。
重点看什么: 看它的 Architecture 章节。它详细描述了“计算节点”和“通信节点”是如何分离的,以及它是如何支持 Kubernetes (KubeFATE) 部署的。
2. FedML —— 模块化系统设计的典范
论文标题: “FedML: A Research Library and Benchmark for Federated Machine Learning Systems” (NeurIPS 2020)
为什么推荐:
它把 FL 系统拆解成了:
Core(算法),API(接口),Mobile/IoT(端侧)。重点看什么: 它的系统分层设计图。特别是它如何定义 Worker (你的容器) 和 Server 之间的通信接口。
第二类:系统优化与调度(系统顶会,用于提升逼格)
这两篇是发在 OSDI(操作系统设计与实现,系统领域的奥林匹克)上的。引用它们证明你的研究品味很高。
3. Oort —— 节点选择与效率
论文标题: “Oort: Efficient Federated Learning via Guided Participant Selection” (OSDI ‘21)
为什么推荐:
虽然它偏向 Cross-Device,但它讨论的核心问题是:如何在异构环境下(有的快、有的慢)提升系统效率。
重点看什么: 看它怎么建模 System Efficiency(系统效率)。即使在医院场景,你也需要考虑如果一家医院的服务器太慢了该怎么办。
4. REFL (或类似资源调度论文) —— 资源敏感
备选搜索方向: 建议直接搜 “Resource-Aware Federated Learning on Kubernetes” 或 “Serverless Federated Learning”。
推荐论文: “FedScale: Benchmarking Model and System Performance of Federated Learning at Scale” (ICML ‘22)
- 重点看什么: 它的 System Configurations 章节。它详细列出了真实世界中 FL 系统的带宽限制、计算延迟分布。这对你搭建实验环境(模拟医院网络)是绝佳的数据来源。
第三类:医疗场景落地(应用背景,用于对齐业务)
5. 宾夕法尼亚大学的脑肿瘤分割研究
论文标题: “Federated learning in medicine: facilitating multi-institutional collaborations without sharing patient data” (Nature Scientific Reports, 2020, Sheller et al.)
为什么推荐:
这是医疗 + 跨孤岛联邦学习最经典的案例之一(虽然发在综合刊,但引用极高)。
重点看什么: 看它描述的 Deployment Challenges(部署挑战)。它里面提到了医院防火墙、数据标准化、容器化部署的实际痛点。
话术: “我看过 Sheller 团队关于脑肿瘤分割的论文,他们提到的多机构协作中的数据异构问题,正是我系统设计中想要通过容器化环境来解决的重点。”
建议明天的阅读顺序(救急版)
今晚时间有限,不要试图通读全文,请按这个顺序“扫射”:
先看 FATE 的架构图:脑子里先有个“跨孤岛系统”长什么样的概念。
再看 Sheller 的医疗论文:搞清楚医院到底痛在哪里(数据不出域、环境不统一)。
最后看 Oort 的 Introduction:学会用“System Efficiency”和“Straggler Problem”这些专业术语来包装你的研究目标。
